利用python备份新浪微博(仅文字)
使用python3.7爬取新浪微博内容并保存到txt文件。如果有需要保存图片的可以参考之前的文章:网络第一篇python爬取图文到word(图文间隔混排)
本教程与之前的python系列文章不同之处在于,使用的是直接调取微博公开的开放接口,返回的是json数据,之前爬取的时候是对返回的html网页数据进行正则处理或使用BeautifuSoup包进行处理!
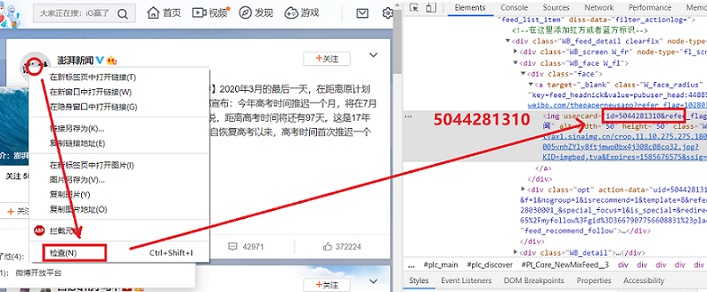
开始之前请明确你要备份的新浪微博的用户id串号,方法很简单,现在网页上登录微博,然后找到你要备份的微博的人的微博头像右键“检查”会打开浏览器的调试窗口并定位到 usercard 这里就是用户id
下面上获取全部新浪微博内容的源码,为了避免因请求频次过快导致被新浪限制请合理使用time.sleep。另外代码中加入了一些判断,觉得影响效率的可以删掉。这个版本根据网上的代码修改而来,但是之前的版本获取方式测试时只获取了不到100页的微博内容(在没做请求频次限制前只获取了12页)。下面公开的python源码已实测过滤获取了2500+的微博内容。还是那句话如果没有代理这类的化还是控制号频次!
import urllib.request
import json
import random
import time
#定义要爬取的微博大V的微博ID
id='5044281310'
#设置代理IP
#proxy_addr="122.241.72.191:808"
proxy_addr=""#为空则不使用代理
#定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
if url != '':
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
else:
opener=urllib.request.build_opener(urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
#获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
#获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:"+name+"\n"+"微博主页地址:"+profile_url+"\n"+"微博头像地址:"+profile_image_url+"\n"+"是否认证:"+str(verified)+"\n"+"微博说明:"+description+"\n"+"关注人数:"+str(guanzhu)+"\n"+"粉丝数:"+str(fensi)+"\n"+"性别:"+gender+"\n"+"微博等级:"+str(urank)+"\n")
#获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
since_id = 0
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id #new
containerid = get_containerid(url) #new
last_weibo_id = 0
while True:
#原始获取微博的方式达到指定次数后可能被限制# url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
#原始获取微博的方式达到指定次数后可能被限制# weibo_url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id+'&containerid='+get_containerid(url)+'&page='+str(i)
if since_id == 0:#本if函数是根据最新版微博接口设计,方便更有效地取得数据
weibo_url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id+'&containerid='+containerid
else:
weibo_url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id+'&containerid='+containerid+'&since_id='+str(since_id)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
since_id = content.get('cardlistInfo').get('since_id')
print('下次请求开始的微博内容id:'+str(since_id))
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count')
comments_count=mblog.get('comments_count')
created_at=mblog.get('created_at')
reposts_count=mblog.get('reposts_count')
scheme=cards[j].get('scheme')
text=mblog.get('text')
if i ==1:#当再次出现第一条微博id的时候,说明已经获取完毕了
last_weibo_id = mblog.get('id')
else:
if last_weibo_id == mblog.get('id'):
print('微博数据获取完毕!')
pass
with open(file,'a',encoding='utf-8') as fh:
fh.write("----第"+str(i)+"页,第"+str(j)+"条微博----"+"\n")
fh.write("微博地址:"+str(scheme)+"\n"+"发布时间:"+str(created_at)+"\n"+"微博内容:"+text+"\n"+"点赞数:"+str(attitudes_count)+"\n"+"评论数:"+str(comments_count)+"\n"+"转发数:"+str(reposts_count)+"\n")
i+=1
#time.sleep(3)#加入延时 抓取频次过快可能会被限制!
time.sleep(random.randint(3,5))#
else:
break
except Exception as e:
print(e)
pass
if __name__=="__main__":
file=id+".txt"
get_userInfo(id)
get_weibo(id,file)

如果对搜集到的微博内容及信息不满意,可以自己用浏览器F12到Network里面去看下微博接口返回的json格式,取出你想要的内容即可。

发表评论