python+selenium+chrome调试模式登录淘宝规避登陆滑动条检测
之前写过一篇使用代理方式规避淘宝登录时selenium框架被检测出来的方法(Python+selenium+mitmproxy登录淘宝规避登陆滑动条检测),今天分享一个利用chrome调试debug的方法来避免selenium被检测。
原理就是使用chrome的debug模式先打开一个debug浏览器窗口,然后在你的python代码中链接到该chrome调试浏览器进行操作。
环境准备:
1、chrome浏览器以及与之版本相对应的chromedriver
2、python3.7环境
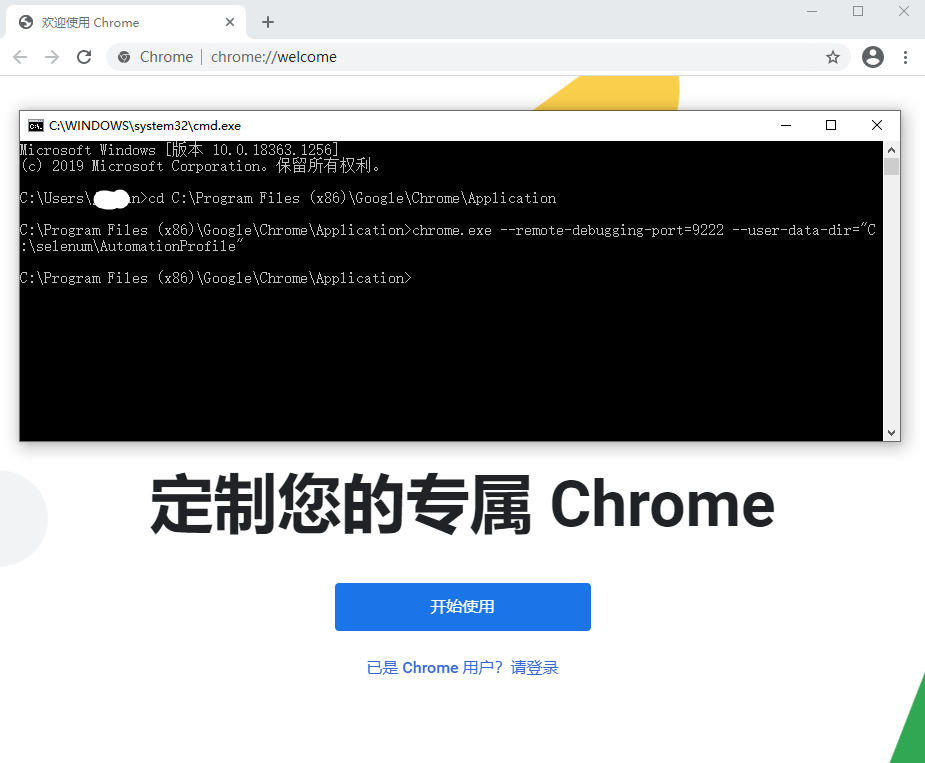
一、在dos窗口中打开chrome的调试窗口
1、找到chrome浏览器的安装位置一般在C:Program Files (x86)GoogleChromeApplication
2、打开dos窗口,使用cd命令切换到第一步找到的目录(注意不要直接在“开始–运行”里面直接执行后面第3步的调试启动命令!)

3、执行以下命令,即可打开chrome的debug窗口,注意不要关闭该浏览器!
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:selenumAutomationProfile"
二、在python脚本中使用调试代理登录淘宝
下面这个是供参考的代码片段(可忽略),用于在python中直接链接已打开的chrome调试浏览器,注意代理的地址和端口要跟第一步骤中的启动命令端口对应上。
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option('debuggerAddress','127.0.0.1:9222')
browser = webdriver.Chrome(executable_path="chromedriver.exe",chrome_options=chrome_options)
browser.get('https://login.taobao.com')
下面是正式的测试代码,代码是从本文开篇介绍的之前教程(对应该文章的第五步骤第2小点:Chrome版,使用selenium+chromedriver.exe)修改而来,有兴趣的可以看看哪边做了改动。
# -*- coding:UTF-8 -*-
#综合改进版本
import time
from datetime import date, timedelta
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.options import Options
import platform
import read
import os
TB_LOGIN_URL = 'https://login.taobao.com/member/login.jhtml'
SELECT_URL = 'https://buyertrade.taobao.com/trade/itemlist/list_bought_items.htm'
class Login:
def __init__(self, account, password):
self.browser = None
self.account = account
self.password = password
def open(self, url):
self.browser.get(url)
self.browser.implicitly_wait(20)
def start(self):
# 1 初始化浏览器
self.init_browser()
# 2 打开淘宝登录页
self.browser.get(TB_LOGIN_URL)
time.sleep(1)
# 3 输入用户名
self.write_username(self.account)
time.sleep(1.5)
# 4 输入密码
self.write_password(self.password)
time.sleep(1.5)
# 5 如果有滑块 移动滑块
if self.lock_exist():
self.unlock()
# 6 点击登录按钮
self.submit()
# 7 登录成功,直接请求页面
print("登录成功,跳转至目标页面进行处理")
#这里可以写一些登录后需要python处理的逻辑
#self.browser.get('https://buyertrade.taobao.com/trade/itemlist/list_bought_items.htm')
print("over")
time.sleep(5000)
def switch_to_password_mode(self):
"""
切换到密码模式
:return:
"""
if self.browser.find_element_by_id('J_QRCodeLogin').is_displayed():
self.browser.find_element_by_id('J_Quick2Static').click()
def write_username(self, username):
"""
输入账号
:param username:
:return:
"""
try:
username_input_element = self.browser.find_element_by_id('fm-login-id')
except:
username_input_element = self.browser.find_element_by_id('TPL_username_1')
username_input_element.clear()
username_input_element.send_keys(username)
def write_password(self, password):
"""
输入密码
:param password:
:return:
"""
try:
password_input_element = self.browser.find_element_by_id("fm-login-password")
except:
password_input_element = self.browser.find_element_by_id('TPL_password_1')
#
password_input_element.clear()
password_input_element.send_keys(password)
def lock_exist(self):
"""
判断是否存在滑动验证
:return:
"""
return self.is_element_exist('#nc_1_wrapper') and self.browser.find_element_by_id(
'nc_1_wrapper').is_displayed()
def unlock(self):
"""
执行滑动解锁
:return:
"""
if self.is_element_exist("#nocaptcha > div > span > a"):
self.browser.find_element_by_css_selector("#nocaptcha > div > span > a").click()
bar_element = self.browser.find_element_by_id('nc_1_n1z')
ActionChains(self.browser).drag_and_drop_by_offset(bar_element, 258, 0).perform()
if self.is_element_exist("#nocaptcha > div > span > a"):
self.unlock()
time.sleep(0.5)
def submit(self):
"""
提交登录
:return:
"""
try:
self.browser.find_element_by_css_selector("#login-form > div.fm-btn > button").click()
except:
self.browser.find_element_by_id('J_SubmitStatic').click()
time.sleep(0.5)
if self.is_element_exist("#J_Message"):
self.write_password(self.password)
self.submit()
time.sleep(5)
def navigate_to_target_page(self):
pass
# def init_date(self):
# date_offset = 0
# self.today_date = (date.today() + timedelta(days=-date_offset)).strftime("%Y-%m-%d")
# self.yesterday_date = (date.today() + timedelta(days=-date_offset-1)).strftime("%Y-%m-%d")
def init_browser(self):
self.downloadPath = os.getcwd()
CHROME_DRIVER = os.path.abspath(os.path.dirname(os.getcwd())) + os.sep + 'chromedriver' + os.sep
if platform.system() == 'Windows':
CHROME_DRIVER = os.getcwd() + os.sep + 'chromedriver87.0.4280.88.exe'
if platform.system() == 'Linux':
CHROME_DRIVER = os.getcwd() + os.sep + 'chromedriver'
"""
初始化selenium浏览器
:return:
"""
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Host": "buyertrade.taobao.com",
"Accept-Language": "zh-CN",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0",
"Connection": "keep-alive",
"referer": "https://buyertrade.taobao.com/trade/itemlist/list_bought_items.htm"
}
"""
options = Options()
# options.add_argument("--headless")
# prefs = {"profile.managed_default_content_settings.images": 2}
prefs = {"profile.managed_default_content_settings.images": 2, 'download.default_directory': self.downloadPath}
# 1是加载图片,2是不加载图片
options.add_experimental_option("prefs", prefs)
options.add_argument('--proxy-server=http://127.0.0.1:9000')
options.add_argument('disable-infobars')
options.add_argument('--no-sandbox')
self.browser = webdriver.Chrome(executable_path=CHROME_DRIVER, options=options)
self.browser.implicitly_wait(3)
self.browser.maximize_window()
"""
options = webdriver.ChromeOptions()
#远程调试下prefs配置不可用,如果要禁止显示图片须在打开的调试浏览器中手动设置
options.add_experimental_option('debuggerAddress','127.0.0.1:9222')
self.browser = webdriver.Chrome(executable_path=CHROME_DRIVER,options=options)
def is_element_exist(self, selector):
"""
检查是否存在指定元素
:param selector:
:return:
"""
try:
self.browser.find_element_by_css_selector(selector)
return True
except NoSuchElementException:
return False
account = 'ranjuan.cn'
# 输入你的账号名
password = '密码'
# 输入你密码
Login(account,password).start()
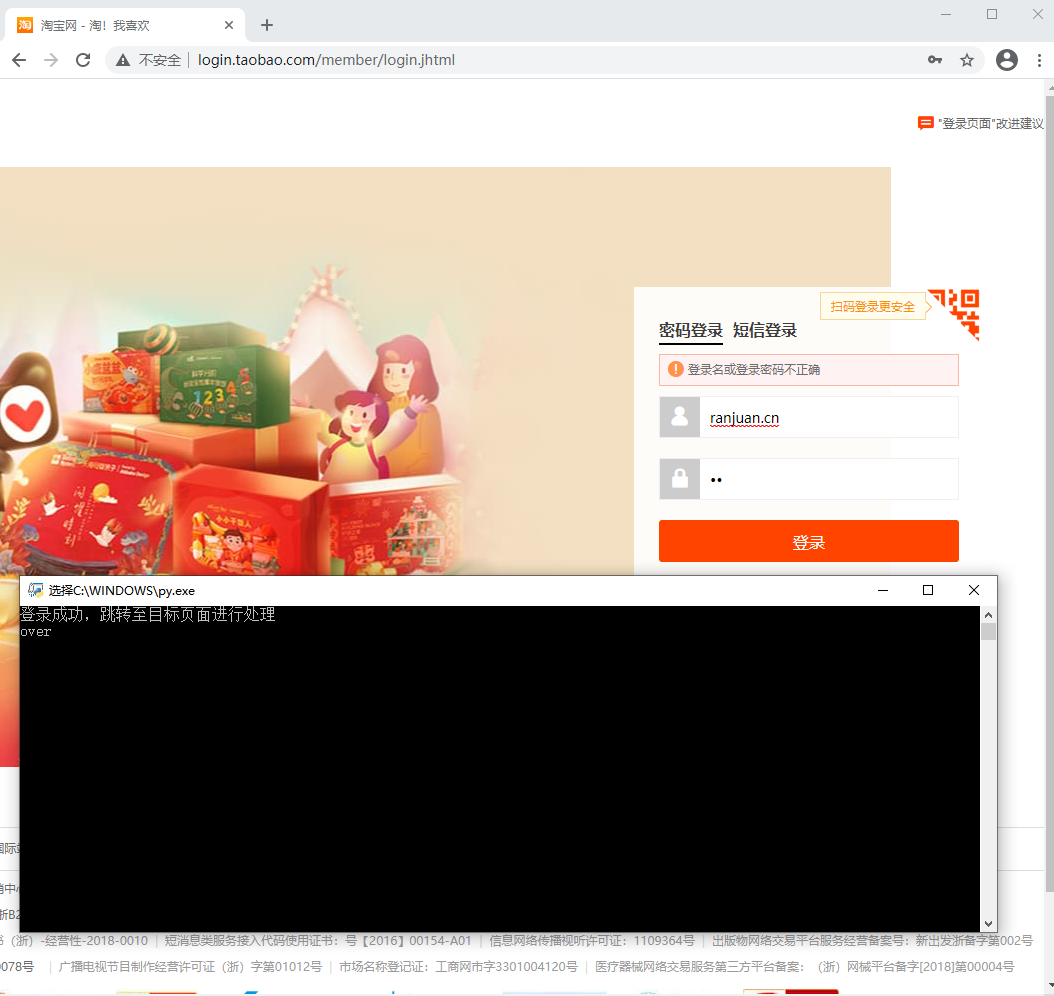
可以看到使用浏览器调试方法打开的网页也不存在使用代理安装证书或该浏览器特征值的方式来避免淘宝的滑块验证。
三、使用chrome调试模式的优缺点
1、可确保操作的连贯性,你可以先打开浏览器调试窗口,然后进行登录。这些准备工作做完后,直接上python接管浏览器去进行操作。 它与selenium直接使用webdriver驱动浏览相比,调试的浏览器不会因为python程序结束而退出!可以通过启用或结束python程序的运行实现手动浏览器操作与python接管浏览器操作的切换。
2、每次调试浏览器执行的操作不会影响到正式使用的chrome浏览器,debug调试中的配置会随着调试浏览器的关闭而结束。
3、这种方式也并不是100%不会被网站检测出的,现在已有的一些自动化及机器人探测js代码,还是能够通过一些特殊方式检测出来的。就算你能通过程序特征检测,如果你的程序操作太过频繁或比较“怪异”还是会被行为分析出来,轻则警告阻断/暂封ip,重则直接封用户账号/吃官司。
4、它太能吃内存了。本来日常浏览器只使用chrome还开了很多标签页,加上chrome本事就是内存大户,这会儿再开个调试浏览器窗口,说实话我的电脑有点卡。

发表评论